The FactEngine Architecture
You already have a Knowledge Graph
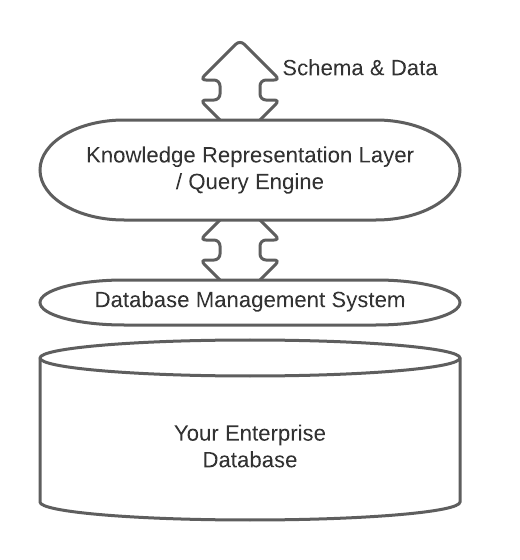
The FactEngine initiative is designed to radically rethink the notion of a database and give you the tools to work with the technology you already have to build your knowledge graph…because you already have one.
Of late, some companies have been trying to sell you dedicated knowledge graph and dedicated graph databases. This, largely because it suits their purposes to convince you to part with your money, time and energy and invest in new technology. This isn’t necessary.
The Paradigm Shift
The paradigm shift is to realise that…
“It is not how your data is stored that makes a graph database or a knowledge graph…it is the model, metamodel and query language that you have over your database that determines whether you have a graph database or a knowledge graph.”
In an earlier article, I introduced the concept in “What is a graph database?”. Here I reintroduce a visualisation of an Object-Role Model morphing to graph and entity relationship models:

In essence, if you apply a knowledge representation/engineering or even reasoning model over your database, it is not a function of how the data is stored that you are interested in…it is what you can do with your database quickly and easily. Using a knowledge representation language such as Object-Role Modeling gives you the ability to perceive of your database as either relational or graph based.
Performance, scalability, etc you can leave to your database vendor. Putting zeal and politics aside if you can…the relational/SQL database SQL Server, for example, claims to be the fastest database around, and it is a hybrid graph and relational database. So, I feel we need to be critical of graph database vendors who try and convince you that you need a dedicated graph database to enjoy speedy graph queries.
Without writing a treatise on Object-Role Modeling (ORM) here…I invite you to convince yourself that ORM is a language suitable for knowledge representation. I introduced some of the concepts in an earlier article on Towards Data Science, “Why learn Object-Role Modeling?”.
Indeed, this article promotes the notion that connected data is the purview of nearly all databases on the market, not solely dedicated graph databases. That is, with the right architecture over your database you can enjoy all the benefits of a graph database or a dedicated knowledge graph…FactEngine just happens to implement that architecture.
For instance, the GRAKN database uses knowledge representation over a Cassandra database [1] and is a database in name. In the same way, FactEngine uses knowledge representation over any compatible database. The paradigm is knowledge representation over an existing database coupled with a time-saving query language.
Connected Data — You already have it
If you have a relational database, your data is already connected…what you want is a way to query that data in an easy to use graph query language. When you use Object-Role Modeling as the mapping overlay over your database….it is as easy as:

A typical FactEngine graph query looks like the below:

Not limited to Relational Databases
The “Knowledge representation over an extant database architecture” is not limited to relational databases, you can equally apply the architecture over a graph database. Basically, all you need do is translate your natural language graph query to either SQL or a graph query language. The first iteration of FactEngine sees us using ODBC and SQL because it covers the most widely used databases, and databases that have decades of research and development to provide you with all of the things you expect from a professional database (ACID compliance, scalability, data typing, security, sharding, etc etc etc etc).
Those relational databases that support recursive queries already support the goodies that you want to perform the classic “friend of a friend of a friend” type queries erroneously attributed as the domain suited to dedicated graph databases.
The best of both worlds
Usually, when you buy a dedicated graph database, you are stuck with the features of that database, including its query language. The architecture represented here lets you have the best of both worlds…you get to query your database in a graph query language and SQL, or whatever query language your database has.
It can’t be that easy!
It really is that easy…conceptually! Once you make the paradigm shift to visualise your database with a knowledge representation language like Object-Role Modeling over your database, all you need focus on is how you would like to query the database. Given the option of graph queries, I feel most people would take it. Graph queries are simple to write compared to SQL.
Where is the technology at?
The FactEngine architecture is already a reality. Straight forward graph queries over a relational database is a reality. FactEngine is focusing future development on recursive queries and the implementation of knowledge engineering rules over the database.
There is a good reason you chose the database you have…why throw out the baby with the bathwater and move to a dedicated graph database if you don’t have to?
References
- Messina A. et al, July 2017, “BioGrakn: A Knowledge Graph-Based Semantic Database for Biomedical Sciences”, Advances in Intelligent Systems and Computing.